
1月16日,阿里云通义开源全新的数学推理过程奖励模型Qwen2.5-Math-PRM,72B及7B尺寸模型性能均大幅超越同类开源过程奖励模型;在识别推理错误步骤能力上,Qwen2.5-Math-PRM以7B的小尺寸就超越了GPT-4o。同时,通义团队还开源首个步骤级的评估标准 ProcessBench,填补了大模型推理过程错误评估的空白。
在当前大模型推理过程中,不时存在逻辑错误或编造看似合理的推理步骤,如何准确识破过程谬误并减少它,对增强大模型推理能力、提升推理可信度尤为关键。过程奖励模型(Process Reward Model, PRM)为解决这一问题提供了一种极有前景的新方法:PRM对推理过程中的每一步行为都进行评估及反馈,帮助模型更好学习和优化推理策略,最终提升大模型推理能力。
基于PRM的理念,通义团队提出了一种简单有效的过程奖励数据构造方法,将PRM模型常用的蒙特卡洛估计方法(MC estimation)与大模型判断(LLM-as-a-judge)创新融合,提供更可靠的推理过程反馈。通义团队基于Qwen2.5-Math-Instruct模型进行微调,从而得到72B及7B的Qwen2.5-Math-PRM模型,模型的数据利用率和评测性能表现均显著提高。
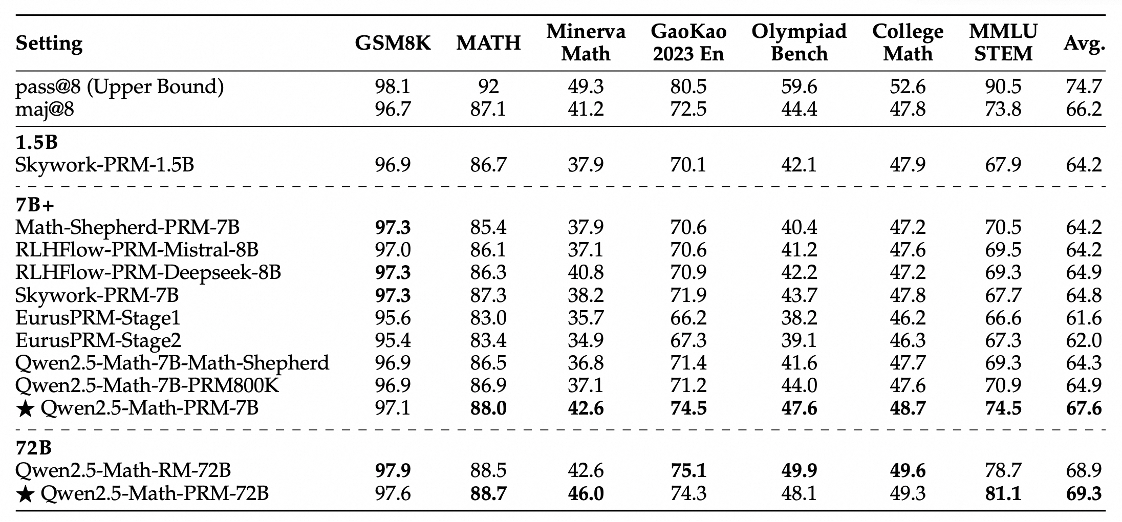
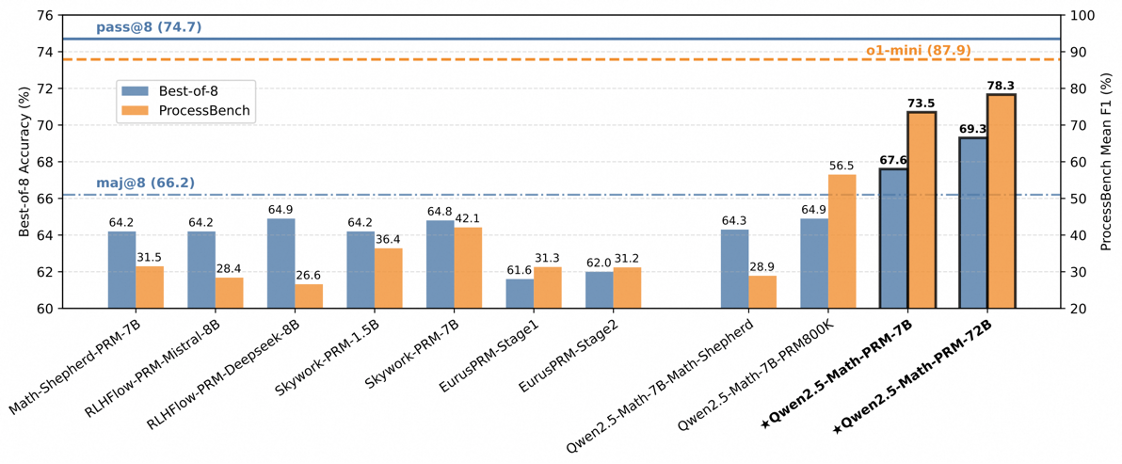
在包含GSM8K、MATH、Minerva Math等7个数学基准测试的 Best-of-N 评测中,Qwen2.5-Math-PRM-7B性能表现超越了同尺寸的开源PRMs;Qwen2.5-Math-PRM-72B的整体性能在评测中拔得头筹,优于同尺寸ORM(Outcome Reward Model )结果奖励模型Qwen2.5-Math-RM-72B。
同时,为更好衡量模型识别数学推理中错误步骤的能力,通义团队提出了全新的评估标准ProcessBench。该基准由3400个数学问题测试案例组成,其中还包含奥赛难度的题目,每个案例都有人类专家标注的逐步推理过程,可综合全面评估模型识别错误步骤能力。这一评估标准也已开源。
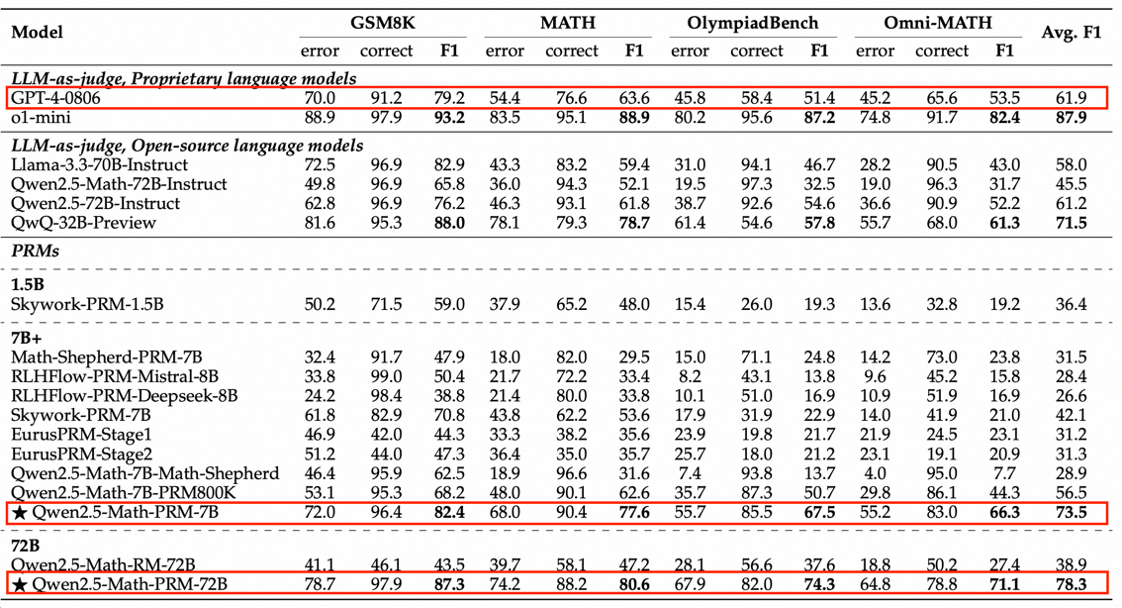
在ProcessBench上对错误步骤的识别能力的评估中,72B及7B尺寸的Qwen2.5-Math-PRM均显示出显著的优势,7B版本的PRM模型不但超越同尺寸开源PRM模型,甚至超越了闭源GPT-4o-0806。这印证了过程奖励模型PRM可有效提升推理可靠性,对未来推理过程监督技术的研发提供新思路。







