

高带宽存储器(HBM)的销量正在飙升,这是因为需要由最先进的人工智能(AI)加速器、图形处理单元(GPU)和高性能计算(HPC)应用快速处理的数据量持续爆炸式增长。
得益于在开发和改进大型语言模型(如ChatGPT)方面的大量努力和投资,HBM库存已售罄。HBM是存储创建这些模型所需大量数据的首选内存,而通过增加更多层数来增加密度的变化,以及SRAM缩放的限制,正在为HBM的紧张库存火上浇油。
需求强劲
“随着大型语言模型(LLM)的参数量现已超过万亿并持续增长,克服内存带宽和容量的瓶颈对于满足AI训练和推理的实时性能要求至关重要。”Rambus硅IP部门的高级副总裁兼总经理Neeraj Paliwal表示。
这种势头至少有一部分来源于先进的封装技术,在很多情况下,这种技术可以提供比平面SoC更短、更快、更可靠的数据路径。“前沿封装技术正在迅猛发展,”日月光投资者关系负责人Ken Hsiang在最近的一次财报电话会议上表示,“无论是AI、网络还是其他在研产品,对我们先进互连技术及其各种形式的需求看起来都非常乐观。”
这正是HBM完美契合的地方。“HBM架构即将迎来一波大潮——定制化HBM。”三星半导体DRAM产品规划副总裁兼负责人Indong Kim在最近的一次演讲中表示,“AI基础设施的普及需要极致的效率和扩展能力,我们与主要客户一致认为,基于HBM的AI定制化将是关键的一步。PPA(功率、性能和面积)是AI解决方案的关键,而定制化在PPA方面将提供显著的价值。”
过去,经济因素严重限制了HBM的广泛应用。硅中介层价格昂贵,而在前道工艺(FEOL)晶圆厂中处理大量硅通孔(TSV)的内存单元也是如此。“随着HPC、AI和机器学习需求的增加,中介层尺寸显著增大。”日月光工程和技术营销高级总监Lihong Cao表示,“高成本是2.5D硅中介层硅通孔技术的关键缺点。”
尽管这限制了其对大众市场吸引力,但对于成本不那么敏感的应用领域,如数据中心,需求依然强劲。HBM的带宽是其他任何内存技术都无法匹敌的,而使用硅中介层、微凸块和硅通孔的2.5D集成已成为事实上的标准。
客户希望获得更好的性能,这就是为什么HBM制造商正在考虑对凸块、底部填充和模塑材料进行改进,同时从8层到12层再到16层DRAM模块的飞跃的原因,这些模块能够以闪电般的速度处理数据。HBM3E(扩展)模块的处理速度为4.8TB/s(HBM3),并有望在HBM4达到1TB/s。HBM4实现这一目标的一种方式是将数据线数量从HBM3的1024条增加到2048条。
HBM三巨头之争
目前,有三家公司生产HBM内存模块——美光、三星和SK海力士。尽管它们都使用硅通孔和微凸块来交付其可靠的DRAM堆叠和配套设备,以便集成到先进封装中,但每家公司采用的方法略有不同。三星和美光正在采用非导电膜(NCF)并在每个凸块级别使用热压键合(TCB)。与此同时,SK海力士继续采用倒装芯片大规模回流工艺的模塑底部填充(MR-MUF),该工艺将堆叠密封在高导电性模塑材料中。
垂直连接在HBM中是通过使用铜TSV和堆叠的DRAM芯片之间的缩放微凸块来实现的。下部缓冲器/逻辑芯片为每个DRAM提供数据路径。可靠性问题主要取决于在回流、键合和模具背面研磨过程中的热机械应力。识别潜在问题需要测试高温工作寿命(HTOL)、温度和湿度偏置(THB)以及温度循环。为了确定各层之间的粘附水平,还纳入了预条件处理和无偏置湿度及应力测试(uHAST)。此外,还需要进行其他测试以确保长期使用过程中微凸块不会出现短路、金属桥接或芯片与微凸块之间的界面分层等问题。混合键合是替代HBM4代产品中微凸块的一个选项,但前提是产量目标无法实现。
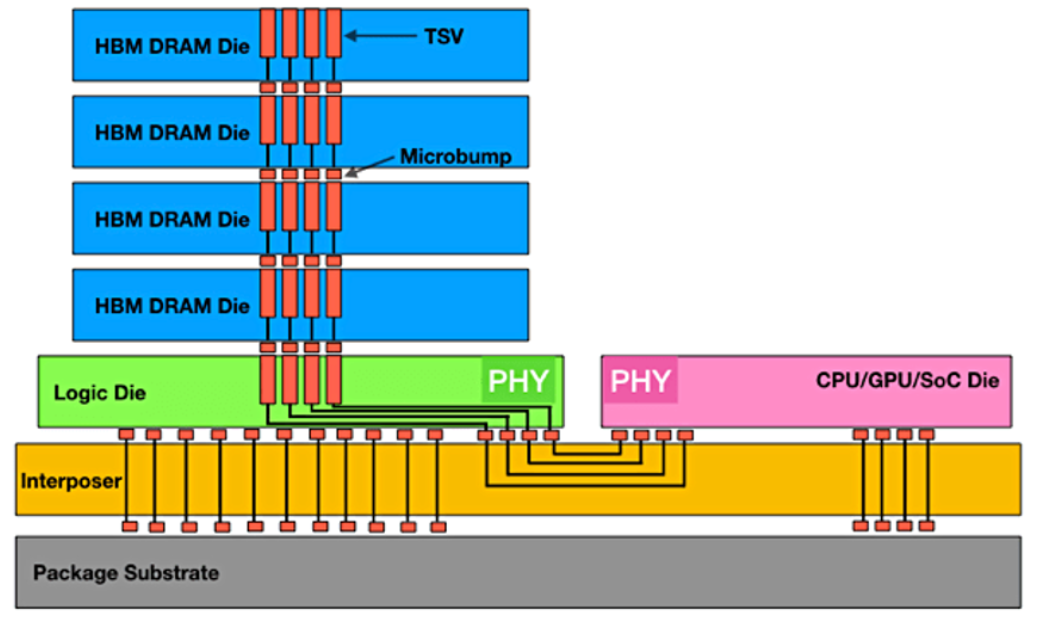
图1:最大数据吞吐量的HBM堆叠。来源:Rambus
另一个正在开发中的进步涉及3D DRAM设备,类似于3D NAND,将存储单元侧向放置。“3D DRAM堆叠将显著降低功耗和面积,同时消除来自中介层的性能障碍。”三星的Indong Kim表示,“将内存控制器从SoC移至基础裸片(base die)将使更多的逻辑空间用于AI功能。我们坚信定制HBM将开启一个新的性能和效率水平。紧密集成的内存和代工能力将为大规模部署提供更快的上市时间和最高质量。”

图2:三星的DRAM规划和创新。来源:Semiconductor Engineering/MemCon 2024
总体趋势是将逻辑更靠近内存,以便在内存或靠近内存的地方进行更多处理,而不是将数据移动到一个或多个处理元素。但从系统设计的角度来看,这比听起来要复杂得多。
“这是一个激动人心的时刻。想要跟随AI热潮,HBM就是关键。各大内存制造商正在争分夺秒,希望成为首家生产下一代HBM的公司。”泛林集团先进封装技术总监CheePing Lee表示。
下一代产品是HBM4,JEDEC(固态技术协会)正忙于制定这些模块的标准。与此同时,JEDEC将HBM3E标准的最大内存模块厚度从720毫米扩展到775毫米,这仍然允许使用40微米厚的Chiplet(小芯片)。HBM标准规定了每引脚传输速率、每堆叠的最大芯片数、最大封装容量(以GB为单位)和带宽。符合这些标准的设计和工艺简化有助于更快地将HBM产品推向市场——现在每两年更新一次。即将出台的HBM4标准将定义24Gb和32Gb级别,以及4层、8层、12层和16层TSV堆叠。
HBM的演变
HBM的发展可追溯至2008年的研发,旨在解决计算内存功耗和占用面积不断增加的问题。“当时,作为最高带宽DRAM的GDDR5,其带宽限于28GB/s(7Gbps/引脚 x 32 I/Os)。”三星的Sungmock Ha及其同事表示,“另一方面,HBM2通过将I/O数量增加到1024个,而不是降低频率至2.4Gbps,实现307.2GB/s的带宽。从HBM2E开始,采用17nm高k金属栅极技术,达到每引脚3.6Gbps和460.8GB/s的带宽。现在,HBM3新引入每引脚6.4Gbps的传输速率,并采用8至12个芯片堆叠,这比上一代带宽提高约2倍。”
这只是一部分。HBM一直在向处理器靠近以提升性能,这为多种处理选项打开了大门。
大规模回流是最成熟且最经济的焊接选项。“通常情况下,只要可能,就会使用大规模回流,因为安装的资本支出很大,成本相对较低,”Amkor(安靠)工程和技术营销副总裁Curtis Zwenger表示。“大规模回流继续提供一种经济有效的方法,用于将芯片和先进模块连接到封装基板。然而,随着性能预期的提高,以及HI(异构集成)模块和先进基板的解决方案空间,一个净效应是HI模块和基板的翘曲量增加。热压和R-LAB(反向激光辅助键合)都是对传统MR的工艺增强,以更好地处理更高的翘曲,无论是在HI模块层面还是封装层面。”
微凸块金属化经过优化以提高可靠性。如果微凸块与焊盘之间的互连采用传统的回流工艺,并使用助焊剂和底部填充材料用于细间距应用,底部填充空洞的捕获和残留的助焊剂可能会在凸块之间造成夹持。为了解决这些问题,预涂非导电膜(NCF)可以替代助焊剂、底部填充材料和键合工艺,在一站式键合过程中无需担心底部填充空洞的捕获和残留的助焊剂。
三星在其12层HBM3E中使用了薄型NCF和热压键合技术,该公司表示,其高度规格与8层堆叠相同,带宽高达1280GB/s,容量为36GB。NCF本质上是含有固化剂和其他添加剂的环氧树脂。该技术会带来额外的好处,尤其是在更高堆叠的情况下,因为业界试图缓解随着芯片变薄而出现的芯片翘曲问题。三星每代产品都会调整其NCF材料的厚度。关键在于完全填充凸块周围的底部填充区域(为凸块提供缓冲),使焊料流动而不留下空洞。
SK海力士首先在其HBM2E产品中从NCF-TCB转换为MR-MUF。导电模材料是与材料供应商共同开发的,可能使用了专有的注射方法。该公司通过其大规模回流工艺展示了更低的晶体管结温。
HBM中的DRAM堆叠放置在缓冲芯片上,随着公司努力将更多逻辑集成到这个基础裸片上以降低功耗,同时将每个DRAM核心连接到处理器,缓冲芯片的功能性不断增强。每个芯片被拾取并放置在载片上,焊料进行回流,最终堆叠经过模塑、背面研磨、清洗,然后切割。台积电和SK海力士宣布,代工厂将向内存制造商提供基础裸片。
“对逻辑上的内存有很大的兴趣。”新思科技研发总监Sutirtha Kabir说,“过去曾研究过内存上的逻辑,也不能排除这种可能性。但每一种方案在功率和热管理方面都会面临挑战,这两者是相辅相成的。直接影响将是热应力,不仅仅是组装级的应力。而且你很可能会使用混合键合,或者非常细间距的键合,那么热挑战对机械应力的影响是什么?”
基础逻辑产生的热量还可能在逻辑和DRAM芯片之间的接口处引起热机械应力。由于HBM模块靠近处理器,逻辑产生的热量不可避免地会散发到内存中。SK海力士高级技术经理Younsoo Kim说:“我们的数据显示,当主芯片温度升高2℃时,HBM侧的温度至少会增加5℃~10℃。”
NCF TCB工艺还需要解决其他问题。热压键合在高温高压下进行,可能会引发2.5D组装问题,例如凸块与底层镍焊盘之间的金属桥接或界面分层。而且TCB是一个低吞吐量工艺。
对于任何多Chiplet堆叠,翘曲问题与贴面材料的膨胀系数(TCE)不匹配有关,这在加工和使用过程中温度循环时会产生应力。应力倾向于集中在痛点——基础裸片和第一个内存芯片之间,以及微凸块层面。仿真产品模型可以帮助解决这些问题,但有时这些问题的全部影响只有在实际产品中才能观察到。
结论
AI应用依赖于多个DRAM芯片、TSV、一个可能包含内存驱动器的基本逻辑芯片,以及多达100个去耦电容的成功组装和封装。与GPU、CPU或其他处理器的结合是一个精心协调的组装过程,其中所有活动部件必须协同一致,以形成高良率和可靠的系统。
随着行业从HBM3向HBM4的过渡,制造高水平的DRAM堆叠的过程只会变得更加复杂。但供应商和芯片制造商也在寻找更低成本的替代方案,以进一步提高这些极快且必要的内存芯片堆叠的采用率。(校对/张杰)
参考链接:https://semiengineering.com/hbm-options-increase-as-ai-demand-soars/







