
10月18日至22日,第58届国际微架构会议(The 58th Annual IEEE/ACM International Symposium on Microarchitecture, MICRO)在韩国首尔召开,中山大学微电子科学与技术学院虞志益教授领导的智能计算芯片团队提出的面向稀疏矩阵乘法的GPGPU存储系统架构相关研究工作被该会议录用并作口头报告。
这一成果的发表是智能计算芯片团队继2024年发表我校首篇MICRO论文后再次连续发表MICRO论文,标志着该团队在GPGPU体系结构和存算一体架构等研究领域具有重要影响。本论文的指导教师是王明羽副教授和虞志益教授,第一作者是中山大学微电子科学与技术学院2023级直博生李晓杰同学,通讯作者是王明羽副教授。本论文得到了国家自然科学基金重大研究计划项目/重点项目/青年项目等支持。

内容摘要
本论文主要针对GPGPU执行稀疏矩阵乘法(SPMM)时内存访问开销大和数据重用率低等问题,提供了一种创新的分层缓存中心计算解决方案(C3ache),探索了如何利用SPMM的行为特征(内存访问模式和计算属性)和GPGPU的内存层次结构来实现近乎最佳的数据重用和内存效率。
在数据流层面,提出混合数据流,结合外积和行积数据流,将SPMM计算解耦为两个具有不同行为特征的不同阶段(乘法和合并阶段),并与缓存行粒度的内存访问模式适配。在架构层面,提出了层次化缓存计算架构,通过缓存内计算将缓存层次结构重构为双模存内计算单元:大规模数据并行处理内存单元和原位合并内存单元。这种架构转换使SPMM的乘法和合并阶段能够映射在相应的重构缓存层次结构中执行。在软件层面,提出了一种新的内存感知压缩格式,专门针对SPMM中的稀疏矩阵编码进行了优化,有效地减少和平衡了内存事务,进一步提高了提出的解决方案的效率。同时,引入多精度矩阵乘法SRAM 存内计算宏来实现。
它不仅为基准GPGPU提供了平均7.22倍的加速比和42.4倍的EDP减少,还与采用以处理器为中心的优化工作稀疏张量核相比,实现了平均2.4倍的加速比和22.9倍的EDP减少。
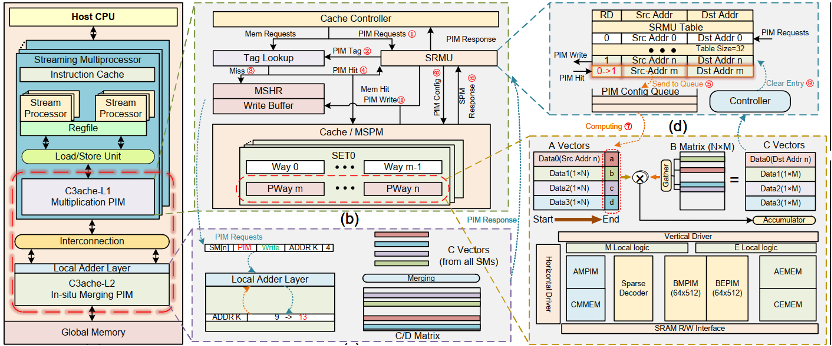
C3ache的整体架构
会议简介
由电气电子工程师协会(IEEE)和美国计算机学会(ACM)共同举办的微架构国际研讨会(MICRO)是最具影响力的体系结构领域顶级会议之一,被公认为与ISCA、HPCA、ASPLOS并列计算机体系结构四大顶会,其中,MICRO是这四大会议中历史最悠久的会议,并且MICRO 还与ISCA作为两大会议入选中国人工智能学会(CAAI)认定的智能芯片与计算机系统领域的A类会议,同时也是中国计算机学会(CCF)推荐的计算机体系结构/并行与分布计算/存储系统领域的A类会议。
据相关统计,自1968年创办以来,截至2025年,前57届MICRO会议总共收录论文2352篇,其中中国大陆高校、科研机构和企业总共发表论文仅约100篇,占比不到5%,而高校发表则更少,MICRO仍是我国学者需要重点关注突破的顶级会议之一。








