
7月4日至7月6日,“以共商促共享 以善治促善智”为主题的2024世界人工智能大会(WAIC 2024)暨人工智能全球治理高级别会议在上海隆重举行。
作为国内领先的智能芯片和基础算力平台企业,爱芯元智在大会上成功举办“芯领未来丨智能芯片及多模态大模型论坛”,论坛以“引领人工智能革新 造就普惠智能生活”为主题,汇聚芯片、大模型、智能制造等领域的专家与意见领袖,共同探讨大模型时代的创新机遇及落地成果。

爱芯元智创始人、董事长仇肖莘在主旨演讲中表示,在AI发展从云端向端侧迁移趋势下,大模型的大规模落地需要云、边、端三级紧密结合,而边缘侧和端侧结合的关键在于高能效的边端AI芯片,更经济、更高效、更环保则将成为智能芯片的关键。由此,大模型一定程度上进入轻量化时代,将由端云协同推动高效落地。
“更经济、更高效、更环保”成AI芯片关键
随着大模型在云端训练逐渐趋于成熟,AI正快速向智能手机、PC和车载等边缘和端侧迁移。仇肖莘表示,智能芯片和多模态大模型已经成为人工智能时代的“黄金组合”。当大模型应用日益广泛,更经济、更高效、更环保将会成为智能芯片的关键词,而搭载AI处理器的高效推理芯片将是大模型落地更合理的选择。

爱芯元智创始人、董事长 仇肖莘
然而,在边缘和端侧应用领域,GPGPU或许并非最最优架构。
仇肖莘进一步表示,“AI芯片一直存在两种路线,即GPGPU和DSA(Domain Special Architecture,专用领域架构处理器)路线。在整个算法或基础网络结构还不稳定时,GPGPU的最大优势在于灵活性,可以适应各种各样的算法和训练方式。”但在过去一两年中,卷积网络的基础结构已趋于稳定,同时大模型的核心架构Transformer基本固定。因此,从运算效率和能耗角度而言,DSA架构优于GPGPU,尤其是边缘和端侧的推理芯片。
例如爱芯元智采用DSA架构的推理芯片能以更小的算力和功耗,实现与英伟达GPGPU芯片的类似性能。其中,爱芯元智AX650N SoC算力为18TOPs,但在能耗相当下,推理性能是英伟达同类100TOPs算力芯片的12倍;若算力相当,AX650N的帧率则是其12倍。仇肖莘指出,芯片作为AI基础设施的底层架构,未来需要更经济、更高效、更环保。
与此同时,随着AI正在从数据中心构筑的云端不断“下沉”,大模型真正大规模落地需要云、边、端三级紧密结合,而边缘侧和端侧结合的关键在于高能效边端AI芯片。
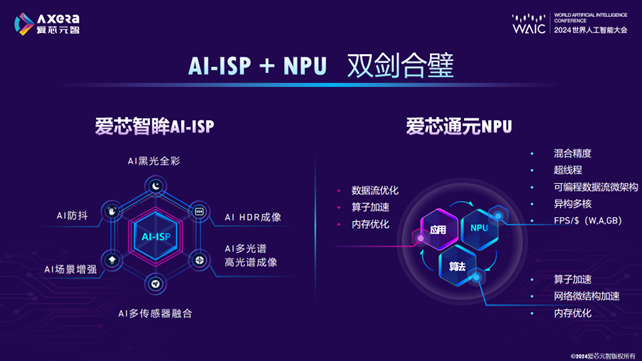
仇肖莘表示,在推进普惠AI的道路上,爱芯元智基于爱芯智眸AI-ISP和爱芯通元混合精度NPU两大自研核心技术,确立了以“AIoT+ADAS”为主的一体两翼战略路线,并向边缘计算、AI推理领域纵深发展,推动智慧城市、智能loT、智能驾驶等应用场景加速落地。
布局全领域算力抢抓AI处理器赛道机遇
在智能时代浪潮下,AI不仅逐渐成为稳定可靠的智能输出基建,而且被视作一场成本驱动型的生产力革命。爱芯元智联合创始人、副总裁刘建伟表示,“AI某种程度上是一种新程序范式,即写程序对应的是模型训练,运行程序对应的模型推理。基于以往数字化浪潮的积累,AI的编程方式已从规则驱动转变为数据驱动,而计算是以Tensor(张量)为主。”
AI计算的基本构成是算子,以及在算子之间的数据流动(即张量数据)。刘建伟称,“通常CPU处理一维数据,GPU处理二三维数据,但张量数据则涉及三、四、五维甚至更高维的数据。由于AI程序的计算密度更高,业界便需要全新的处理器(NPU)应对AI的程序计算。未来,NPU将于CPU、GPU共存,并处理各自最擅长的计算任务。”

爱芯元智联合创始人、副总裁 刘建伟
为了抢抓AI处理器赛道机遇,爱芯元智2022年便率先推出支持原生Transformer模型的高算力、低功耗NPU AI处理器AX650N,为大模型在边缘侧、端侧的应用提供了有力基础。
目前,爱芯元智的爱芯通元混合精度NPU的研发已迭代至第六代,拥有高、中、低三档算力覆盖市场,可应用于以文搜图、通用检测、以图生文、AI Agent等多个模型场景,其中在智慧城市和辅助驾驶等领域实现规模化量产以及出货。该芯片采用多线程异构多核设计,实现了算子、网络微结构、数据流和内存访问优化,并高效支持混合精度算法设计等。
刘建伟介绍称,爱芯元智AI处理器的核心就是算子指令集和数据流DSA微架构。“算子指令集是一个比较宏观的指令。然而,底层采用可编程数据流的微架构能提高能效和算力密度,同时其灵活性也保证了算子指令集的完备性。另外,爱芯元智成熟的软件工具链可以让开发者快速上手,软硬件的联合设计则保障了AI处理器的高速迭代。”
视觉大模型落地物联网与智能驾驶提速
基于算法、芯片、产品的垂直整合以及协同设计开发,爱芯元智致力于打造世界领先的人工智能感知与边缘计算芯片并提供全栈式解决方案,进而帮助客户实现最新技术的快速落地,以及服务智慧城市、智能驾驶、机器人以及AR/VR等巨大的边缘和端侧设备市场。
论坛上,爱芯元智在智慧物联、智能驾驶等领域合作伙伴也分享了AI处理器的应用前景。

智慧物联和人工智能创新融合专家 殷俊
其中,智慧物联和人工智能创新融合专家殷俊表示,以视觉为主的智能大模型在城市治理与生产生活方面应用广泛。近年来,AI大模型在文本、语音等领域快速发展,但在视觉领域的落地却面临可靠性、稳定性、理解不够全面等挑战。对此,真实准确描述客观世界是视觉大模型落地的关键,而行业应用中未来一定需要大量的闭源模型来解决各类难点和特性。
显然,视觉大模型还存在数据量极大,训练成本高,以及应用场景复杂多变等特性。针对不断更新迭代的视觉大模型,殷俊认为,不应该让用户放弃原有的技术投资,而是要通过大小模型协同和模型小型化实现最优算力配置组合,从而加快大模型在行业应用中的落地。
与物联网一样,视觉大模型在智能驾驶领域的应用逐渐风生水起。迈驰智行科技有限公司CTO张弛表示,目前自动驾驶显示出BEV视觉感知媲美Lidar,不依赖高精度地图,以及“端到端”模型等技术趋势,使得BEV+Transformer大模型架构正成为智驾行业主力军。

迈驰智行科技有限公司CTO 张弛
张弛指出,大模型不仅加速自动驾驶从高速公路向更加复杂的城区场景的过渡,推动从显示BEV升级至隐式BEV感知方案,也促进了端到端感知规控一体化的形成。在这一过程中,激光雷达、高精度地图的作用在减弱,而丰富的端到端大模型则让不受地理环境限制的点到点自动驾驶成为可能,但这背后还需要进一步突破优化环境感知、预测决策等技术难点。
智能芯片+大模型助力AI落地和普惠深化
在整个人工智能产业发展中,大模型已成为至关重要的抓手并持续向端侧迁移,而端云协同将推动大模型高效落地。面壁智能副总裁贾超认为,凭借在成本、隐私、延时性、可靠性等方面的优势,端侧AI发展会成为全球趋势,这也意味着大模型正式进入了轻量化时代。
在这一背景下,“模型知识密度平均每8个月提升1倍”将成为大模型时代的新“摩尔定律”。贾超强调,“企业开发端侧大模型需要在算法侧和芯片侧双管齐下,包括采用端侧芯片推进在应用场景上高效落地,这样才能给用户带来最极致的体验。面壁智能打造了全球最强端侧多模态模型“小钢炮”MiniCPM系列,已经在爱芯元智的AI芯片上成功运行。”

面壁智能副总裁 贾超
目前,虽然绝大多数AI芯片均采用Arm指令集架构,但RISC-V架构凭借开源开放、精简、模块化等优势逐渐在全球落地开花,并不断向AI芯片领域深入。在未来大模型的时代,业界将可基于RISC-V设计不同芯片产品,从而提供更强的算力、存力、运力。
阿里巴巴达摩院RISC-V及生态高级技术专家尚云海分析称,“大模型未来会呈现规模大、结构统一、能力增强三大趋势,但如今处于计算需求与硬件计算能力不匹配的阶段,量化、结构化稀疏、低精度训练将成为提升大模型性能的有效路径。RISC-V作为开源架构,可以第一时间适应AI算法和算子的快速变化,满足大模型对AI算力和芯片架构发展的需求。”

达摩院RISC-V及生态高级技术专家 尚云海
与成熟的X86和Arm架构相比,虽然RISC-V在开发工具、软件和环境方面还存在一定差距。不过,尚云海认为,RISC-V具有良好的自定义、可扩充等关键能力,提供覆盖充分的弹性算力,而且在开发周期上较x86和Arm架构大幅提速,将在AI芯片领域大有可为,并且联合爱芯元智的AI处理器一起,为客户提供异构架构的AI芯片。
随着大模型的应用不断推进各行各业智能化转型,智能芯片的突破创新让算力更加有的放矢。以“构建世界一流的感知与计算平台”为愿景,爱芯元智将携手产业界坚定推进智能芯片与大模型的深度融合以及云边端一体化,进而推动大模型落地加速和AI普惠不断深化。








